오늘은 likely, unlikely에 대해 알아보겠습니다.
한창 소스 분석을 할때, likely, unlikely를 본 기억이 있습니다.
전 커널쪽 소스를 많이 봤었고, 커널 소스에서 많이 사용하는 것을 보았고, 실력 향상에 많은 도움이 되었습니다.
그러나 실제 코딩을 할때는 잘 사용하지는 않았던 것 같습니다.
위 두가지의 함수는 컴파일러의 최적화와 연관이 있다고 보시면됩니다.
likely와 unlikely를 함수로 불렀으나, 정의된 곳을 보면 매크로 함수입니다.
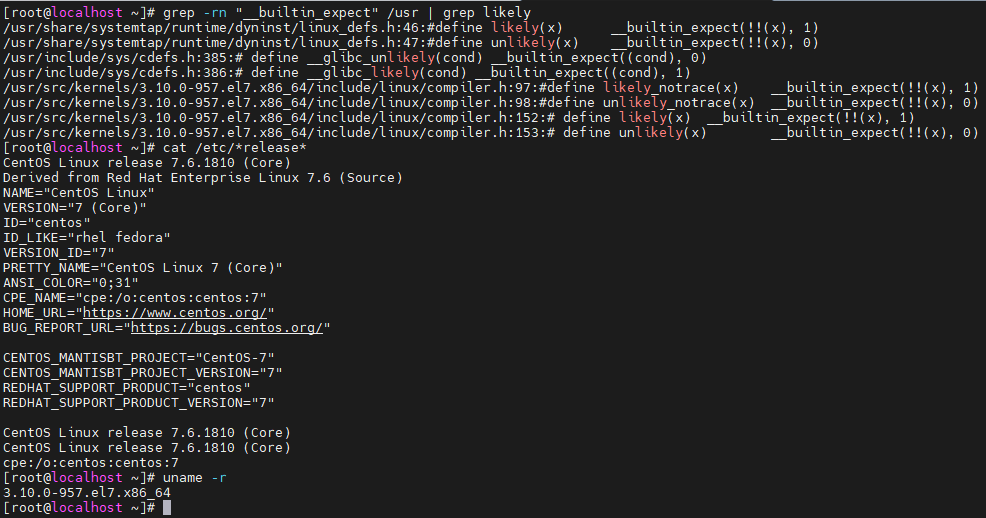
저는 위와 같은 OS환경이고, likely와 unlikely는 위와 같이 정의되어 있습니다.
매크로에는 __builtin_expect 함수를 사용합니다.
그 전에 먼저 분기 예측이라는 말에 대해 알아야됩니다.
------------------------------------------------------------------------------------------------
if ( number == 1 ) {
}
else {
}
------------------------------------------------------------------------------------------------
if문이 있습니다.
아무런 조건없이 위와 같이 코딩을 할 경우, 컴파일러는 number의 값은 1일 확률, 그외의 값일 확률에 대한 정보가 없기 때문에 이것에 대하여 최적화를 하지 않습니다.
프로그래머가 컴파일러에게 아무런 언급을 하지 않았기 때문입니다.
그러나 number 값이 1일 확률이 90%, 그 외일 확률이 10%일 경우에 프로그래머는 컴파일러에게 힌트를 줄 수 있습니다.
"number == 1이 될 확률이 그 외일때 보다 높다"
이 때, 컴파일러는 이에 대하여 조금더 최적화할 수 있습니다.
이것이 분기 예측입니다.
이럴 경우에 프로그래머는 likely나 unlikely(__built_expect)를 사용합니다.
likely 인자에는 참의 값이 주로 오는 경우를 사용하고, unlikely 인자에는 거짓의 경우가 되는 값을 사용합니다.
위의 힌트를 바탕으로 간단하게 예제를 한번 보겠습니다.
------------------------------------------------------------------------------------------------
if(likely(number==1)){
}
else{
}
------------------------------------------------------------------------------------------------
likely를 사용하여 위와 같이 코딩하였다면, 컴파일러에게 해당 if문에서는 number값이 1이 참이 될 확률이 더 높다는 것을 알려줍니다.
위의 코드를 조금 응용하여 unlikely를 사용해보겠습니다.
------------------------------------------------------------------------------------------------
if(unlikely(number!=1)){
}
else{
}
------------------------------------------------------------------------------------------------
unlikely를 사용하여 위와 같이 코딩하였다면, 컴파일러에게 해당 if문에서는 number값이 1아닐 확률이 더 높지 않다는 것을 알려줍니다.
즉, number값이 1이 될 확률이 높다고 컴파일러에게 알려주는 것입니다.
오늘 포스팅은 여기까지입니다.
'프로그래밍 > C' 카테고리의 다른 글
| [C] expected specifier-qualifier-list before, unknown type name 에러 (0) | 2022.07.04 |
|---|---|
| [C] pthread_join 쓰레드 조인 (0) | 2022.05.25 |
| [C] IPC 중에 어떤 걸 선택해야 할까 (0) | 2022.03.27 |
| [C] 소켓 옵션 제어 ( getsockopt, setsockopt ) (2) (0) | 2022.02.27 |
| [C] 소켓 옵션 제어 ( getsockopt, setsockopt ) (1) (0) | 2022.02.23 |
